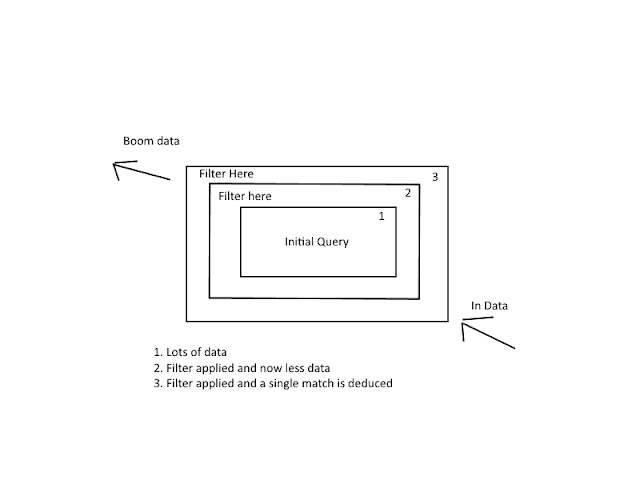
^^Perhaps^^ For various reasons me and my team hadn't been spending a lot of time at the coal face, coding. From spikes, POCs and analysis to release activity - coding opportunities have been few and far between. Thankfully this changed over the last couple of weeks. As part of the Payments Platform we have been given the opportunity to chip away at some of the Legacy processes to provide more flexibility in our Payments offering. Part of this process see's us hoping to consolidate some existing logic to manage the integration with a 3rd party Payment Solution Provider more flexibly. Specifically around handling particular types of payment which are handled differently based on certain criteria such as a customers Billing country, what currency they are paying with and the card type they are using. Stuck In essence the work we are carrying out is a redesign and re-factor of some logic which is spread out in a number of places. Bringing it all in, has been both i